Laboratorio di lancio AI
Mostra come integrare l'AI in un prodotto: lavoro sui dati, regole di sicurezza e controlli qualità prima del lancio.
È disponibile la descrizione del progetto
Nella pagina progetto: cosa è stato realizzato, perché serve al business e come funziona — spiegato in modo semplice.
Web mode shows the demo as a full web app (not inside a phone frame).
Problema
I prototipi AI regrediscono in fretta: formati che si rompono, risposte incoerenti e costi che salgono senza segnali. Servono output prevedibili, qualità misurabile e fallback sicuri prima del rilascio.
Approccio
Trattiamo l'AI come un sistema di prodotto: contratti, valutazione, telemetria e rollout — non solo un prompt.
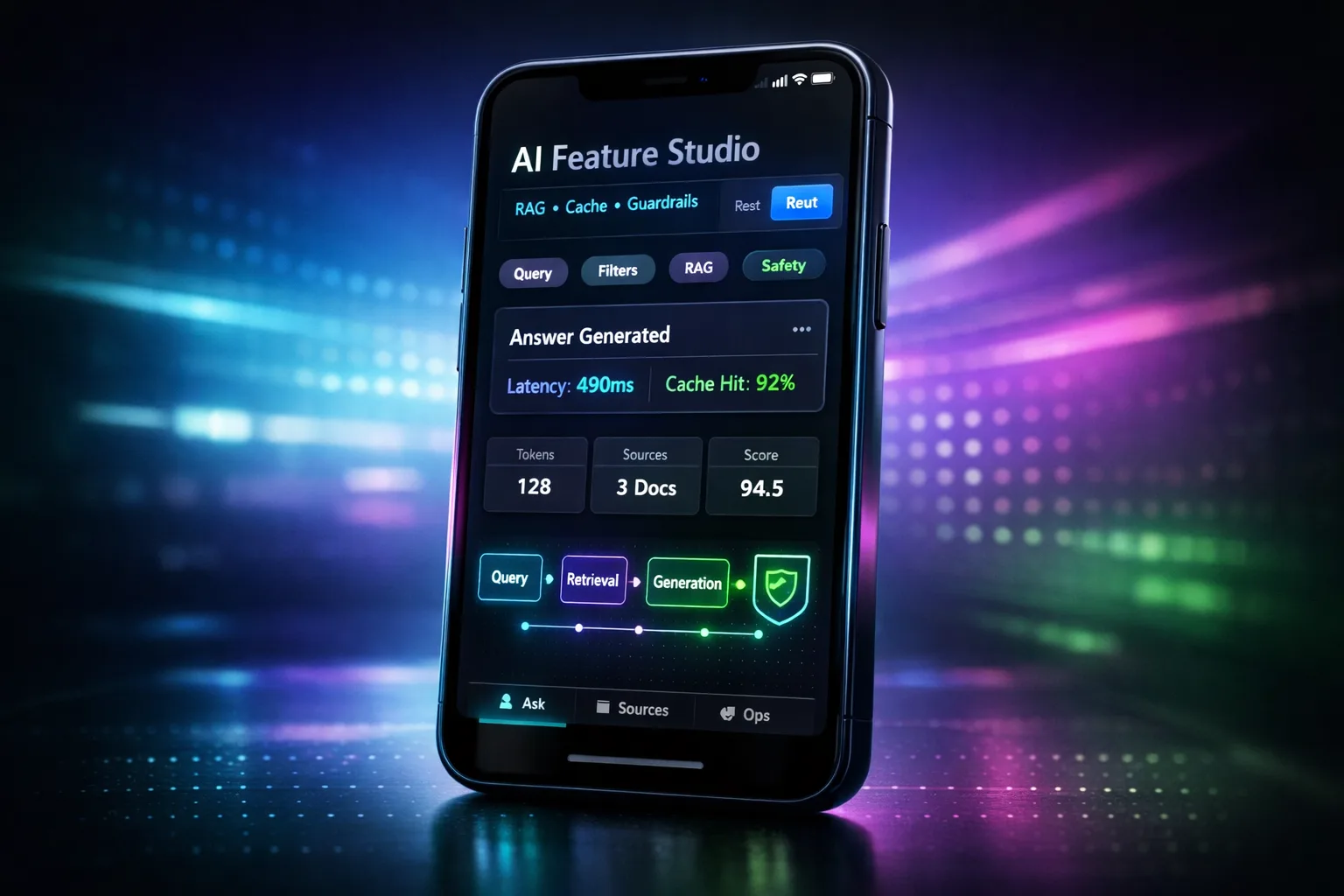
Cosa è stato realizzato
- Pipeline a fasi con guardrail e scoring del rischio
- Vista retrieval con fonti fissate e logica di reranking
- Pannello budget (latenza/token) e note di rilascio (demo)
Risultato
- UX più stabile: meno risposte "casuali" e formati rotti
- Costi più bassi e risposte più rapide grazie a cache e budget
- Decisione chiara go/no-go prima del rilascio
Termini (opzionale)
- RAG: rispondere usando documenti recuperati invece di inventare
- Guardrail: regole che bloccano output non sicuri o non validi
- Eval: test ripetibili che intercettano regressioni
Note tecniche (opzionale)
- Validazione schema e fallback deterministici
- Hook di telemetria per latenza/token (qui simulati)
- Varianti di prompt configurabili (A/B)
Sintesi
Una pipeline AI pronta per la produzione: retrieval, guardrail, budget e readiness di rilascio — simulazione offline.
Cosa è stato realizzato
- Pipeline RAG con cache, reranking e fonti fissate
- Guardrail + scoring del rischio + fallback sicuri
- Dashboard budget: latenza, token e segnali di costo (demo)
Prova
- Inserisci una domanda e premi Run
- Controlla Sources e i documenti fissati
- Guarda Ops: budget e decisioni
Valore per il business
- Percorso più rapido dal prototipo al rilascio stabile, con meno regressioni
- Qualità e costi più prevedibili prima di andare in produzione
Per chi è
Team prodotto che portano feature AI in produzione
Dettagli di implementazione
Metodi
- •Output con schema
- •Rilasci gated da eval
- •Fonti fissate + caching
Stack
Next.jsTypeScriptTailwindSimulatore offline
Architettura
- •Fasi della pipeline con budget espliciti
- •Retrieval → rerank → answer → eval
- •Guardrail + fallback
Note
- →Questa demo è completamente offline per mostrare UX e logica decisionale.